

the broken economics of databases
Why database companies charge so much, earn so little, and keep making things complicated

The database industry has a strange economic problem, and this post attempts to lay out the foundation for why that’s the case. It will cover some concepts from economics 101 and hopefully answer the question “why is it so expensive to pay someone to run my database?”.
The short version is that database vendors have incentives that push them away from simplicity and toward defensibility, resulting in databases that seemingly get worse over time.
Disclaimer: I’m working on an OSS database project called OpenData that was partly motivated by the dynamics in this post, but this is the only time I’ll mention it.
making sense of earnings reports
There is some puzzling data available in historical earnings reports of public database companies that were acquired or shutdown. Cloudera, MariaDB, and Confluent (where I was a relatively early employee) all reported gross margins between 78% and 91%. In the traditional economic sense, gross margins this high are pretty rare and you’d expect these companies to be wildly profitable. It is clear that none of the referenced companies were.
For a database company, gross margins are the ratio between the amount of revenue the company brings in and the cost to “run the database”. The accounting here is pretty loose, but there are in essence two factors that play into the cost: the hardware cost and the operations cost.
The hardware cost is more obviously measurable, this is what the company pays the cloud providers for the hardware. The operations cost is estimated based on the number of engineering hours spent on-call and on “other operational tasks”.
When I was at Confluent, this was the result of a survey that accounting sent out to the engineering teams, asking us how much time we spent on operations. As you can imagine, that’s an imprecise estimate, but investors care a lot about it.

What explains this half of the story is operating margin, which indicates how much of the revenue went toward R&D, Sales & Marketing and Administration. After accounting for that, these companies generated very modest margin (from 2-8%, and deep in the red if you include all GAAP expenses).
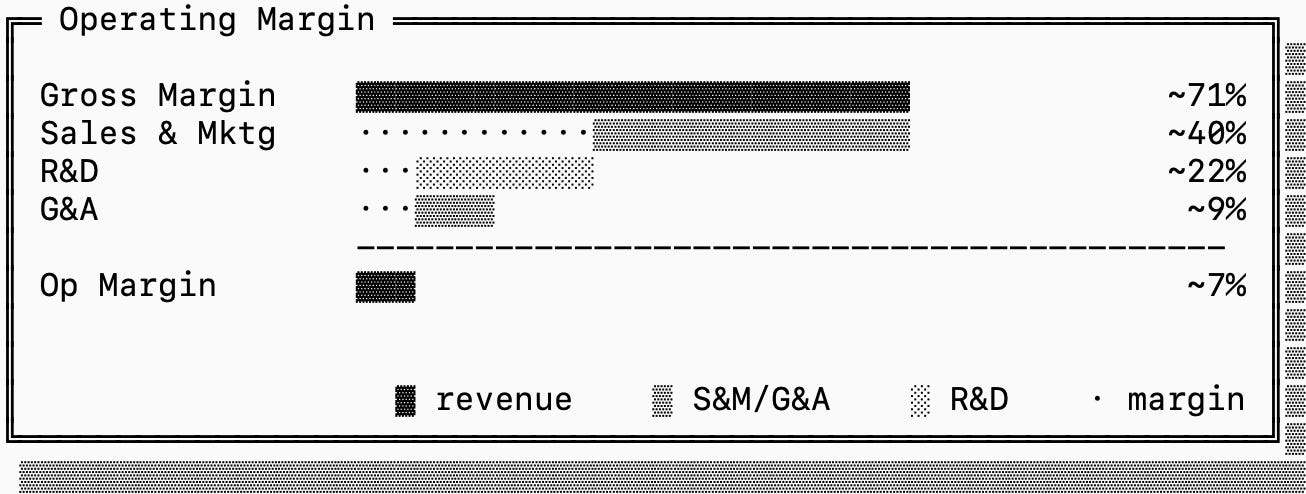
These gross and operating margins are interesting on their own, but together they paint a concerning economic picture: database companies depend on a delicate balance, and even a small sustained dip in gross margins can be fatal.
monopoly and competition
If you aren’t too interested in economic theory or already have a solid foundation, you can skip this section.
In economic theory there’s a spectrum between monopoly markets and perfect competition. At one end, a monopolist has meaningful control over price, and therefore demand. At the other, firms sell effectively identical products into a market with many competitors, so any one firm has almost no pricing power.
Economists represent this by relating marginal revenues MR (revenue from selling one more unit) and marginal costs MC (cost to serve one more unit) with respect to demand. Firms, whether monopolies or not, want to increase output so long as selling one more unit brings in more revenue than cost. This equilibrium is denoted with MR = MC.
We can explore the intuition using a database example. I love to pick on MongoDB because they’re generous enough to have detailed public pricing. An M50 instance is priced at $1,460/mo. They chose this price intentionally.
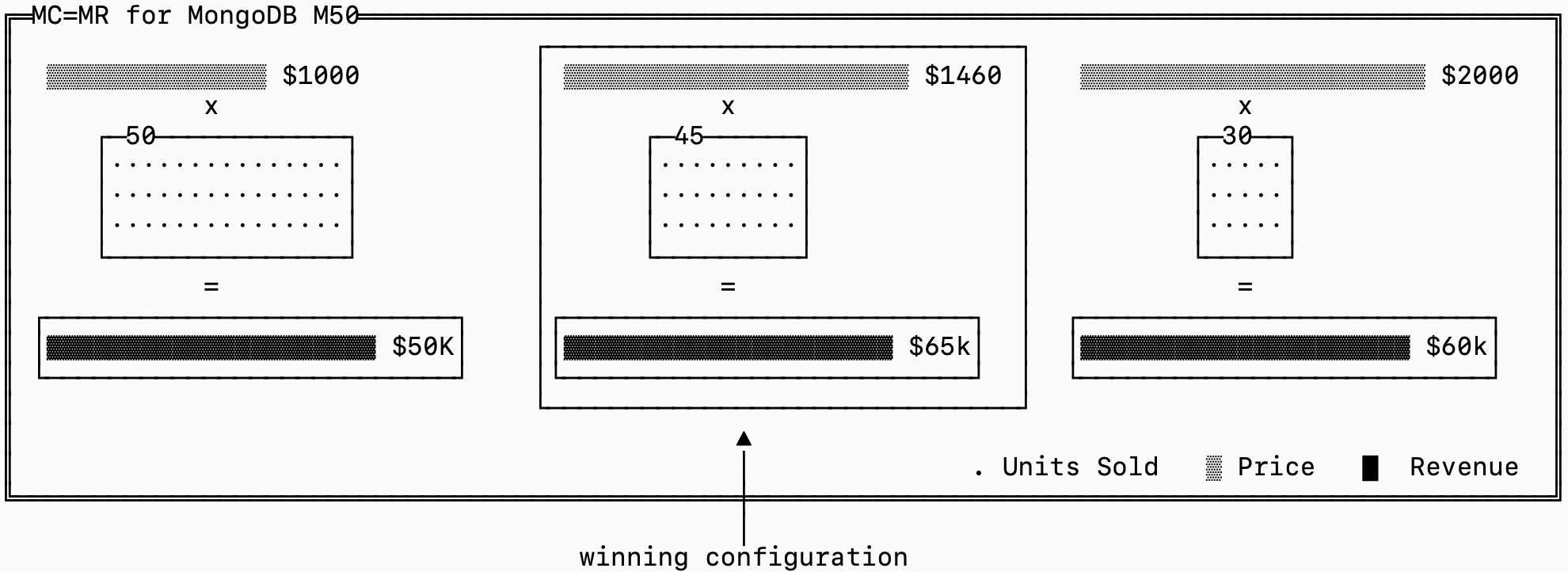
Imagine the alternatives to help understand the intuition behind the MR=MC condition:
At $2,000/month, they would make more on each sale but likely lose enough customers that total profit falls.
At $1,000/month, they would win more customers but probably not enough to make up for the lower revenue per cluster.
Somewhere in between is the “best” point that preserves high margins but remains low enough to avoid losing too much demand.
That math looks very different depending on the shape of the demand curve.
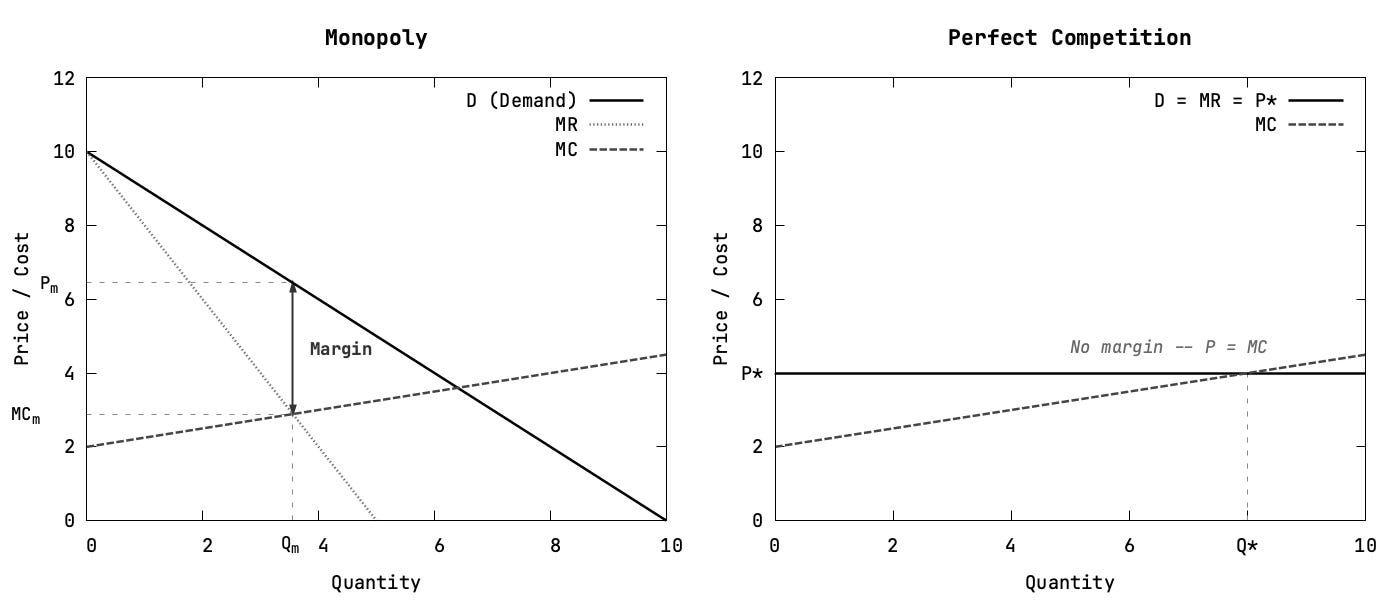
The graphs above show the extreme ends of the spectrum.
In a perfect monopoly, the firm’s own pricing decision meaningfully affects the quantity it can sell. If MongoDB was a true monopoly, customers may dislike the M50 price tag, but they would not have a close substitute to jump to immediately (their only alternative is not having MongoDB).
In perfect competition, the opposite is true. If there were a thousand vendors selling truly identical managed M50 clusters, MongoDB could not raise prices much without losing customers to cheaper alternatives, and it could not sustainably cut prices below cost forever either.
The reality is that MongoDB lives somewhere in the middle. The question for us is what characteristics does the database market as a whole have in the long term?
The answer depends on how “different” databases really are. Postgres and Kafka are relatively different systems and you’re usually ill advised to use them interchangeably. Confluent’s Kafka and Amazon’s MSK, on the other hand, are close substitutes. In economic models, even a single close substitute can quickly erode margins and force vendors to compete on price (the Bertrand Paradox).
That puts significant pressure on vendors to avoid becoming interchangeable, else risk losing their high gross margins.
why vendors need high margins
There’s an interesting parallel to draw between two seemingly unrelated markets: databases and pharmaceuticals. For both, the initial R&D investment to bring a product to market is substantial. Developing a serious database or a successful drug takes years of specialized work, but selling one more unit of either isn’t particularly expensive.
Economists describe this as high fixed costs (the cost to develop the initial product) and low variable costs (the cost to manufacture a single instance of the product). This creates a basic requirement where the initial investment has to be earned back somehow. Whether that happens through high margins, high volume, or both depends on the demand curve we discussed earlier.
There are a few ways that this can play out, and where the comparison with pharma becomes useful. In both industries, the company whose R&D investment results in something genuinely innovative can charge what’s known as Schumpeterian Rent: temporary profits that exist because competitors have not yet caught up. During this period the original company is effectively a monopoly. You can charge as much as you want for Insulin or Kafka if you’re the only one selling it (for now).
The core tension here is that innovation is not the same thing as sustained value capture. Innovation creates temporary pricing power, which unlocks the temporary high gross margin we see in earning reports, but maintaining that requires constant innovation and sustained R&D costs.
In situations like this, who captures value from an innovation is shaped by two factors: appropriability and complementary assets. Appropriability defines how easily an invention can be imitated and the Complementary Assets define what is required to monetize the innovation itself.
The reason the pharmaceutical industry is a useful foil is that it tends to have a stronger answer to both questions. Government-issued patents create a much more formal appropriability regime, and the path from inventing a drug to monetizing it is usually more directly controlled by the innovator (they directly own or have strong relationships with manufacturing).
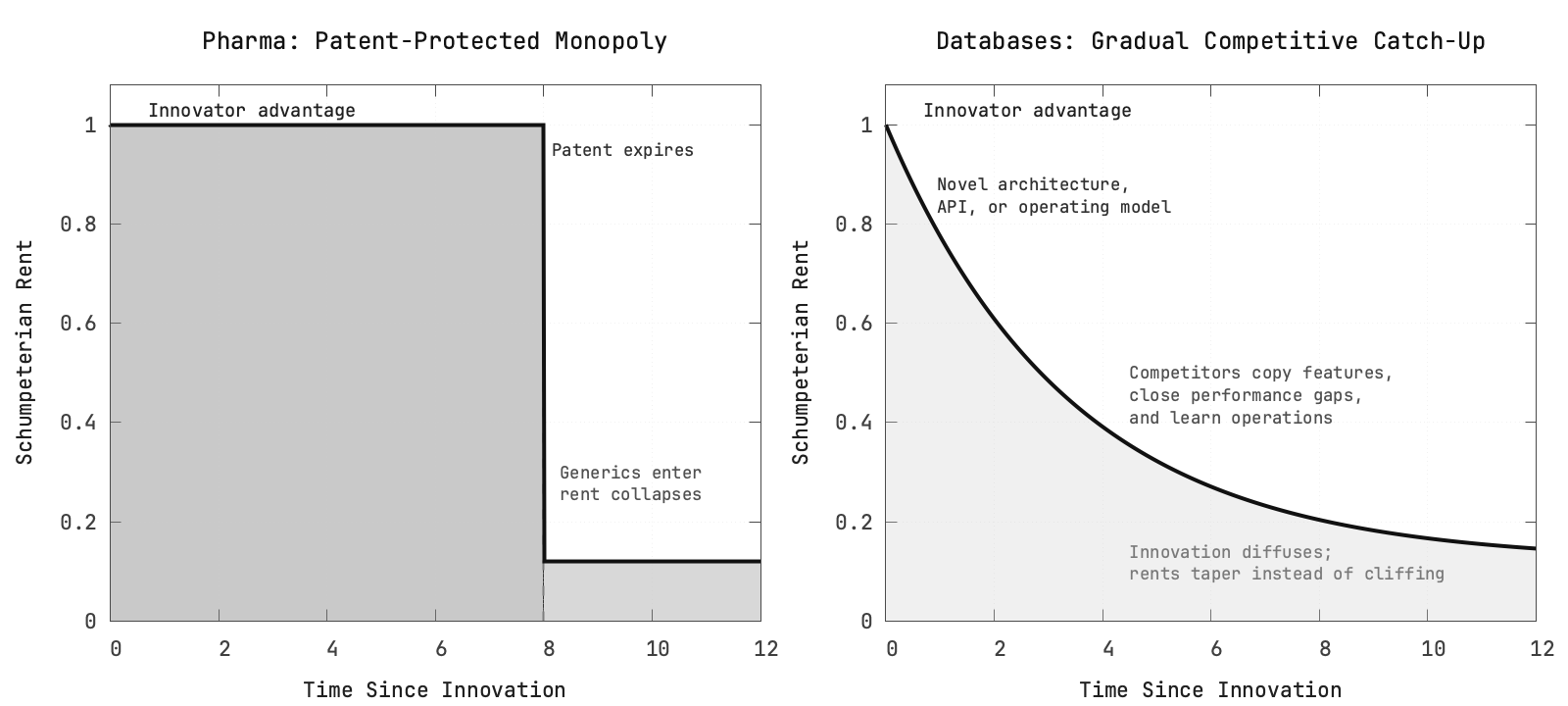
Databases do not get the luxury of government protection, so vendors have to rely on weaker defenses like closed source code, restrictive licenses, and operational know-how. None are reliable barriers in the long term, and the half-life of these protections is quickly degrading with advancements in AI. That means the Schumpeterian rents from database innovation usually decay more gradually and less predictably than they do in pharma.
The bigger problem is in the complementary assets. In pharma, the innovator usually has a much more direct claim on the assets required to commercialize the product. In databases, the crucial complement is the infrastructure and hardware that runs the system, which is typically owned by cloud providers like AWS rather than by the inventor of the database.
This asymmetry is the core of the industry’s strange economics.
Bringing it back to the demand curves and what options are available to database vendors, it starts to make sense why they must sell databases at high margins to survive. They need to recover high fixed costs in a market where the innovation diffuses rapidly, the protection is weak, and the owners of the key complements (the hyperscalers) are structurally better positioned to win a price war.
This means their only strategy is to continuously generate innovations that renew the Schumpeterian advantage, differentiate in some other manner, or fundamentally change their business models. But continuously generating innovation requires additional investment, which has a significant fixed cost and starts the cycle all over again.
why databases become worse over time
This conclusion, on its own, is not especially troubling. It is good that vendors have to keep innovating if they want to earn outsized profits. The problem is that if these innovations run dry, the company ends up resorting to tactics that hurt the product to avoid a price war with AWS.
The unpalatable truth is that the useful feature set of a database stabilizes relatively quickly. Database developers tend to release a wealth of new features to stay ahead of competition, but on average these features don’t get adopted (and at worst cause issues).
When feature development is no longer enough, the focus shifts from pure product improvement to avoiding commoditization.
There are three characteristics of a commodity: fungibility, price transparency, and low switching costs. With a mature database, fungibility tends to rise first. If most buyers view multiple managed offerings of the same database as “close enough,” then the remaining levers of differentiation shift elsewhere.
Some of those levers can be healthy, and even benefit developers. Sometimes a vendor creates high switching costs by providing such tight, high-quality integration across a bundle of services that detangling it is simply not feasible without significant investment. All database companies want this kind of defensibility, but few achieve it. Databricks is one of the clearer success cases.
Some levers are toxic. Vendors can, and do, manufacture price opacity by hiding behind complicated pricing schemes. Snowflake pricing, for example, is so complex that Gartner released a report (available for purchase) that helps you understand and negotiate your bill.
But there is another, more subtle lever: operational complexity.
To see why, we can revisit the MongoDB Atlas example. If you recall, an M50 instance is priced at $1,460/mo but the equivalent cluster of three 1-year reserved r5.xlarge instances in AWS us-east-1 cost only $360/mo (including 160GB EBS volumes). This means that MongoDB thinks it’s reasonable for you to value the operational work they do for you at $1,100/mo, or 3x the hardware cost.
This also means a 50% reduction in hardware cost will reduce your price by ~12% while a 50% reduction in operational costs reduces your price by ~38%, assuming savings are passed on directly to you.
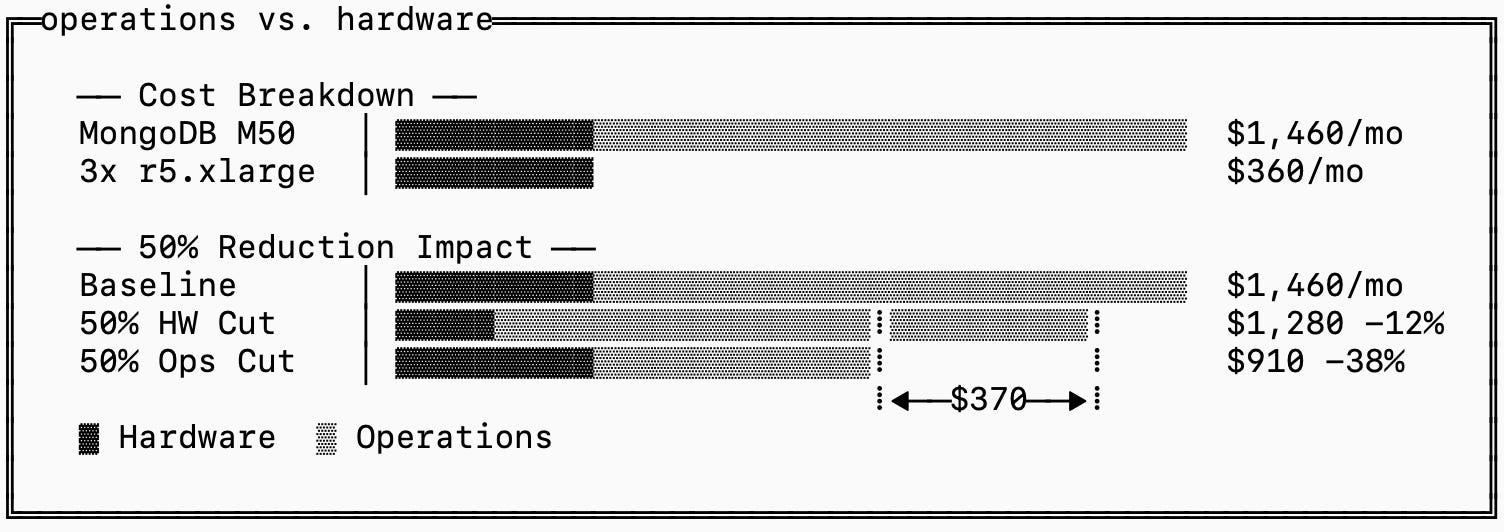
That creates an uncomfortable incentive structure. MongoDB has strong reasons to make operations easier inside Atlas, but weaker reasons to make the database easy for everyone else to operate. Operational expertise is, after all, a large part of what the managed service is selling. If the system becomes dramatically easier to run everywhere, you would be less willing to pay such high margins for their management layer.
In other words, they are incentivized to do the opposite. The tougher it is to operate a database and the more specialized the expertise required, the harder it is for competitors (including the self-hosting alternative) to offer an equivalent experience.
This usually does not happen overtly. I’ve been a database engineer my whole career, and I can guarantee you that we are not sitting around trying to make systems harder to run for no reason. The dynamic is subtler. We are rewarded for adding functionality that helps the product stand out, and each additional layer of functionality tends to make the system more operationally complex. Over time, the database becomes more capable, but also more “interesting” to debug at 3AM when the pager goes off.
To summarize, the market incentivizes defensibility over simplification. This, in turn, results in databases getting “worse” over time.
the end
You may not have sympathy for multi-billion dollar database companies, and that’s fine, but the inconvenient truth is that most database development (and OSS software at large) is funded by enterprise, which means that your user experience is directly dictated by corporate profits. We’ve explored why this may not be in your favor.
You likely also need no proof that the hyperscalers are not a solution to this. Their incentives are not particularly aligned with users either, and they are often happy to capture the value created by upstream database companies and open source communities without taking on the same level of product risk. They are excellent at scaling proven systems, but much less naturally motivated to make the kind of focused, opinionated bets that produce new categories in the first place.
Since I’ve already inundated you with economic theory and this post is quite long, I’ll end it with a glimmer of optimism: I think object storage is already making a different economic model possible. It is generic enough to absorb a large share of the heavy infrastructure burden, while still being simple enough to serve as a foundation for building narrower, more focused systems on top. That changes the fixed-cost equation in a way that could matter a lot, opening up the door to lower-margin business models. You can already see systems like Warpstream, Turbopuffer, and Quickwit taking advantage of it.
But that’s a subject for another post!
Next up, I’ll get back to some deep engineering content and let the economics settle for a bit. As always, thanks for your support and reading bits & pages.