

protocols for transactional usage of object storage
building correct applications w/o external coordination

This edition of Bits & Pages covers the design patterns that allow systems to use Object Storage correctly for online transactional (OLTP) use cases.
This blog is motivated by SlateDB’s transactional write module, which implements some of these protocols for production use.
object storage primitives
The protocols that are outlined in the rest of this blog depend on a small set of APIs that are given to us by all common object storage systems.
write primitives
On the write side we’re given three primitives that we can use:
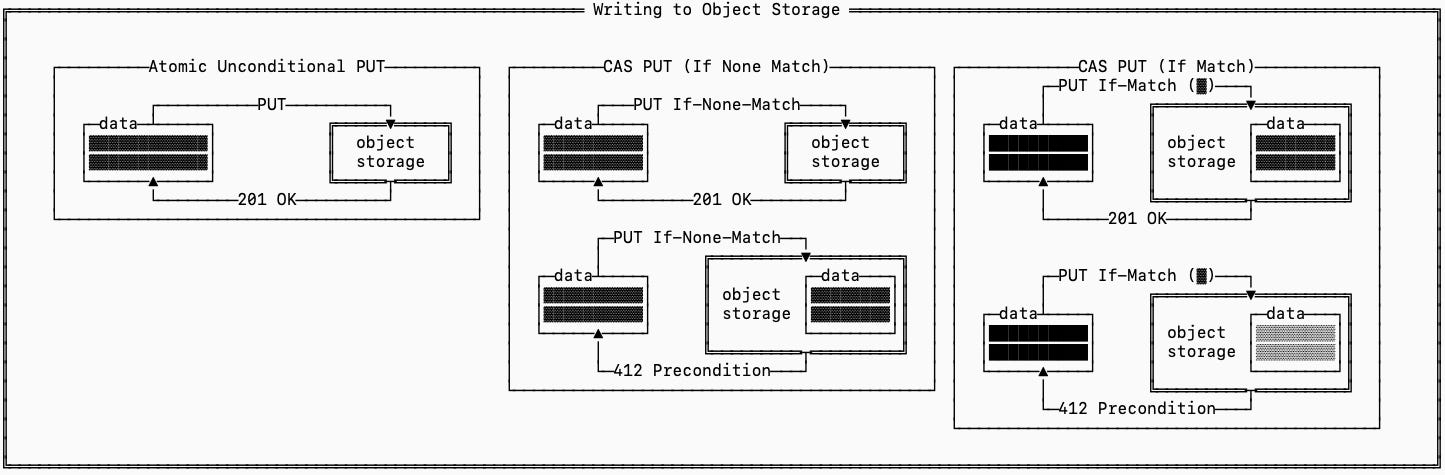
Unconditional Atomic Writes: There’s a normal PUT, which makes sure that data is written atomically. This does not prevent races from happening (i.e. writer A and writer B can write to the same path and there’s no guarantee to whose write wins) but it guarantees that the data written is entirely from one write (there is no interleaving data).
In the context of databases, this is a great way to model writing append-only files with unique IDs, which inherently avoid conflicts. It is not helpful for resolving situations where writes need to coordinate (though you do get read-your-writes, which is helpful for guaranteeing correctness during fail-overs). To do that the next two primitives are used.
Conditional Writes: There are two types of conditional writes that are subtly different but serve the same purpose. PUT If-None-Match and PUT If-Match both use compare-and-set operations on the object store’s metadata service to resolve conflicts. The former will only allow a write to happen if there does not already exist a file with that path. The latter will only allow a write to happen if the file that exists matches the content hash (or generation ID in some implementations) that you pass in.
These are typically used when writing and updating metadata with published, well-known file paths because they enable you to identify when a metadata conflict happened between writers.
Empirically it doesn’t seem like there’s much of an impact on performance whether you use a conditional write or an atomic write.
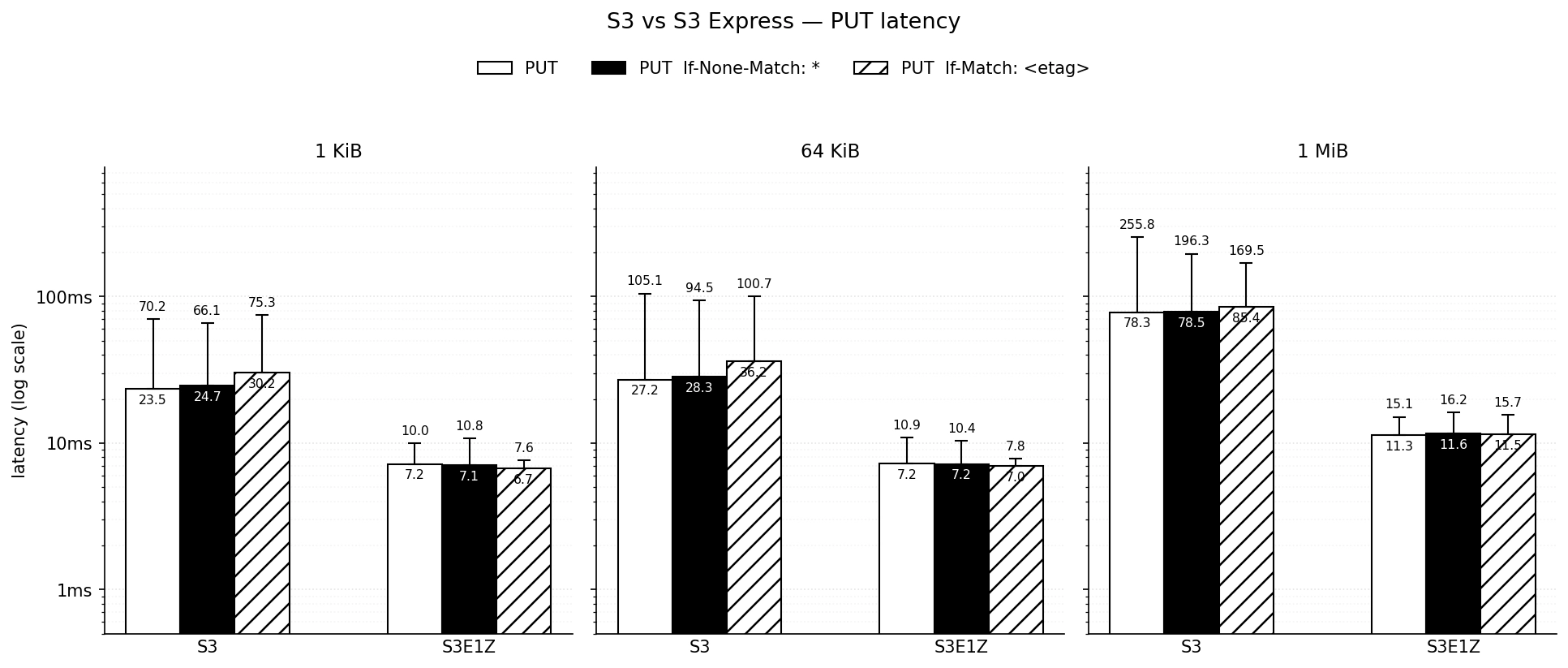
All write ops cost you the same amount, so feel free to use the conditional versions whenever you need to.
read primitives
On the read side, we use three primitives as well:
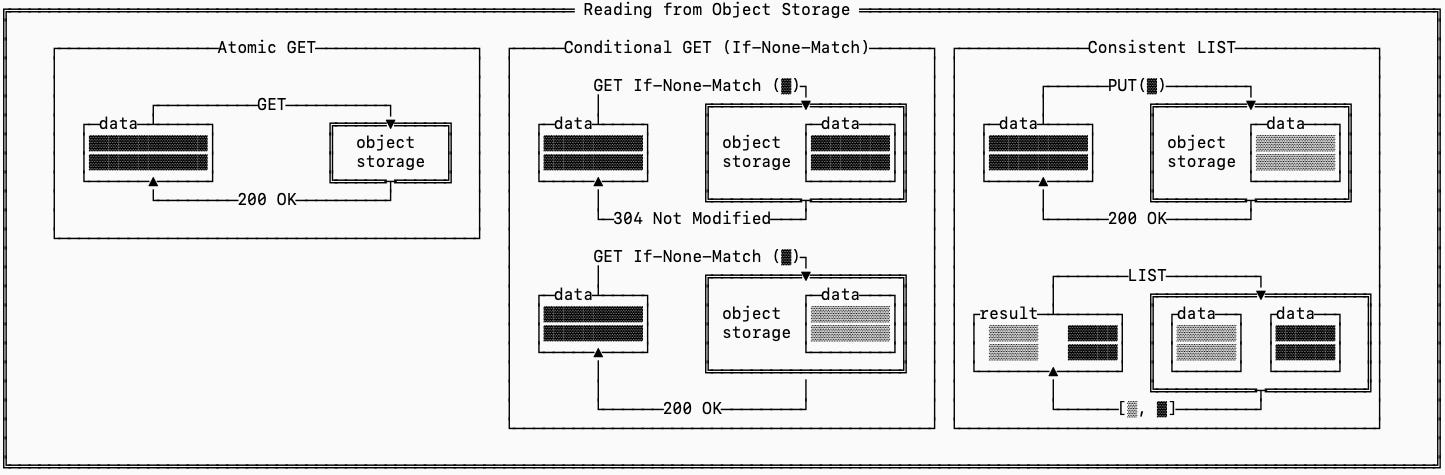
Atomic Reads: A normal GET request from object storage ensures that we will get a fully consistent snapshot of the file that is retrieved. This means that if a racing write to the same file happens, we won’t ever see that write partially applied.
Conditional Reads: Object stores also allow you to use GET If-None-Match to only fetch a file if its tag doesn’t match what you already have. This allows you to serve the request with a metadata-only fast-path, and avoid re-fetching locally cached data that hasn’t changed.
Consistent Listing: Supporting strongly consistent LIST requests means that as soon as a PUT returns 200 the result of that write will be available on subsequent LIST requests. This is typically used for metadata discovery, and prevents expensive conflicts from being discovered when you attempt to read files down the line.
Reads are where it gets interesting from a performance angle. The If-None-Match will quickly return a 304 code if the data has not changed since the last fetch, which allows faster repeated fetches. This opens the door to protocols that read the same file frequently.
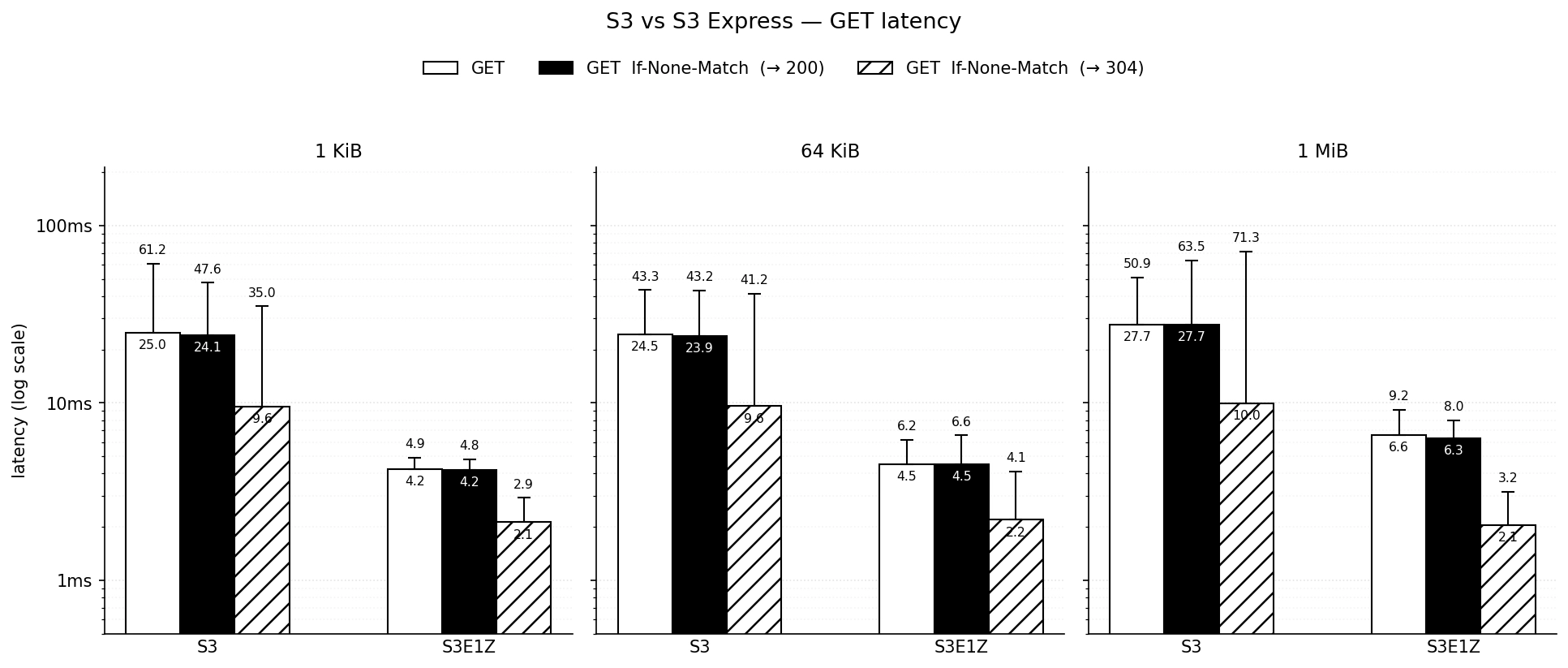
The additional consideration to make is that there are differences in costs for the different read operations. For S3 you can see the following values, the interesting one is that LIST will cost you nearly 12x the amount of a GET.
┌─────────────────────────┬───────────────────┬────────────────────────────────────┐
│ Operation │ $/1K requests │ Body charge │
├─────────────────────────┼───────────────────┼────────────────────────────────────┤
│ GET (unconditional) │ $0.0004 (Class B) │ $0.09/GB egress (internet); │
│ │ │ free same-region │
├─────────────────────────┼───────────────────┼────────────────────────────────────┤
│ GET If-None-Match: │ $0.0004 (Class B) │ $0 on 304; $0.09/GB on 200 │
│ <etag> │ │ │
├─────────────────────────┼───────────────────┼────────────────────────────────────┤
│ LIST │ $0.005 (Class A) │ response payload billed as egress │
│ │ │ (small) │
└─────────────────────────┴───────────────────┴────────────────────────────────────┘protocols for correct transactional usage
The following section assumes a setup where you have applications interacting with databases that are backed by object storage alone. The database will implement correct transactional protocols under different conflict scenarios. We define “correct” as the ability to implement a serializable history of our data system.
When reasoning about these protocols, you should first evaluate whether or not they are safe. Crashes and failures should never result in inconsistent state. The second evaluation criterion is latency and throughput in steady state as well as under contention, when many writers are attempting to access the same files.
baseline protocol
We’ll start with a simple, but correct, database implementation using object storage. I call this protocol the “baseline” protocol, where every write directly goes to object storage using an atomic PUT.
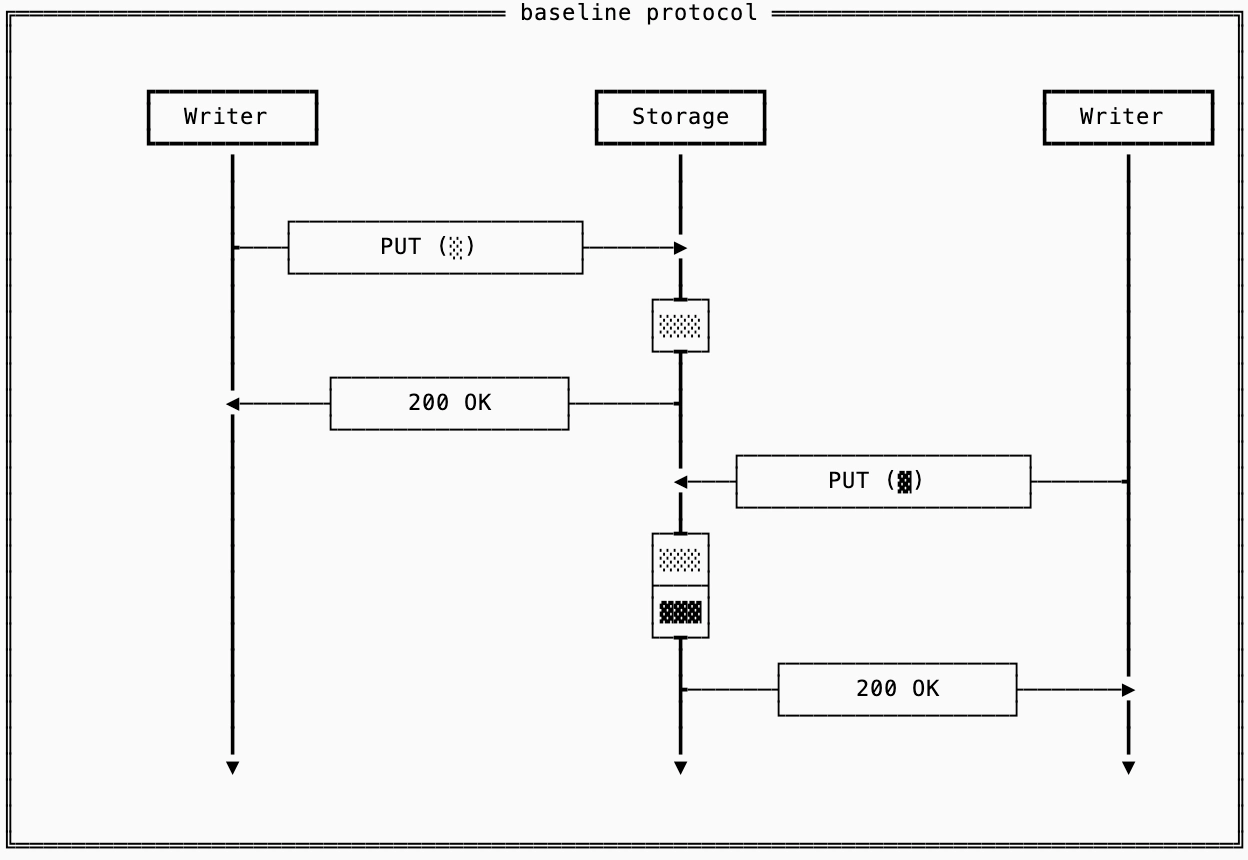
This isn’t an interesting protocol, but it works. If at any point the database crashes, we’ll have only acknowledged writes stored. The downsides are obvious: as we saw in the results in the previous section, object store latencies are high, so your database will be quite slow.
What is interesting about this, is that it illustrates that consistent protocols are possible on object storage because the foundation is consistent itself.
simple conditional protocol
The way to improve the latency problems of the baseline protocol is to batch writes together into one file.
For simplicity, let’s assume that you have a single file that represents your entire database content1. If you were to use the baseline protocol in this scenario, one writer would simply overwrite the data from another in the case of a conflict.
To prevent that, every write can pass in an identifier of what was the last version of the file that it had seen (in S3, this is called the etag and is a hash of the file content) as the condition for accepting the write using PUT If-Match. On a conditional write failure, the conflicting data is re-read, conflicts are resolved, and then the write is retried.
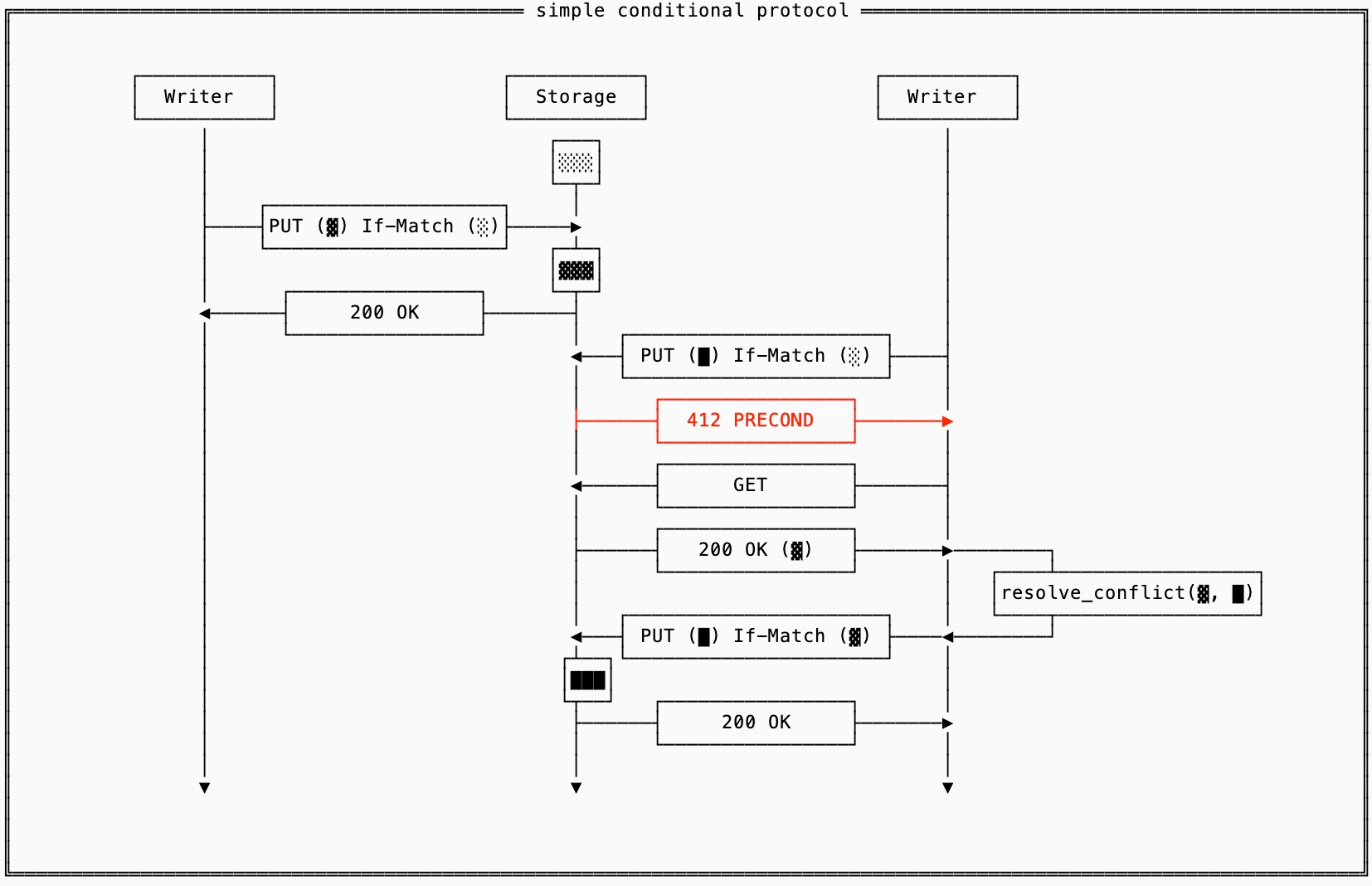
This protocol works great when there is a low rate of contention. Otherwise you can see that the cost of each conflict requires 3 round-trips (the initial attempt, the GET, and the final PUT with the resolved data). If there’s an additional conflict, which very well might happen if the first writer is writing often because it doesn’t need an additional GET to write again, the second writer might get starved.
This is, by the way, the protocol that OpenData Buffer uses for its manifest coordination.
sequenced write protocol
This protocol uses the file name as the guard, as opposed to the contents of the file, by incrementing the file name on every successful write. If the next sequential file already exists, then you know there has been another writer that attempted to write data:
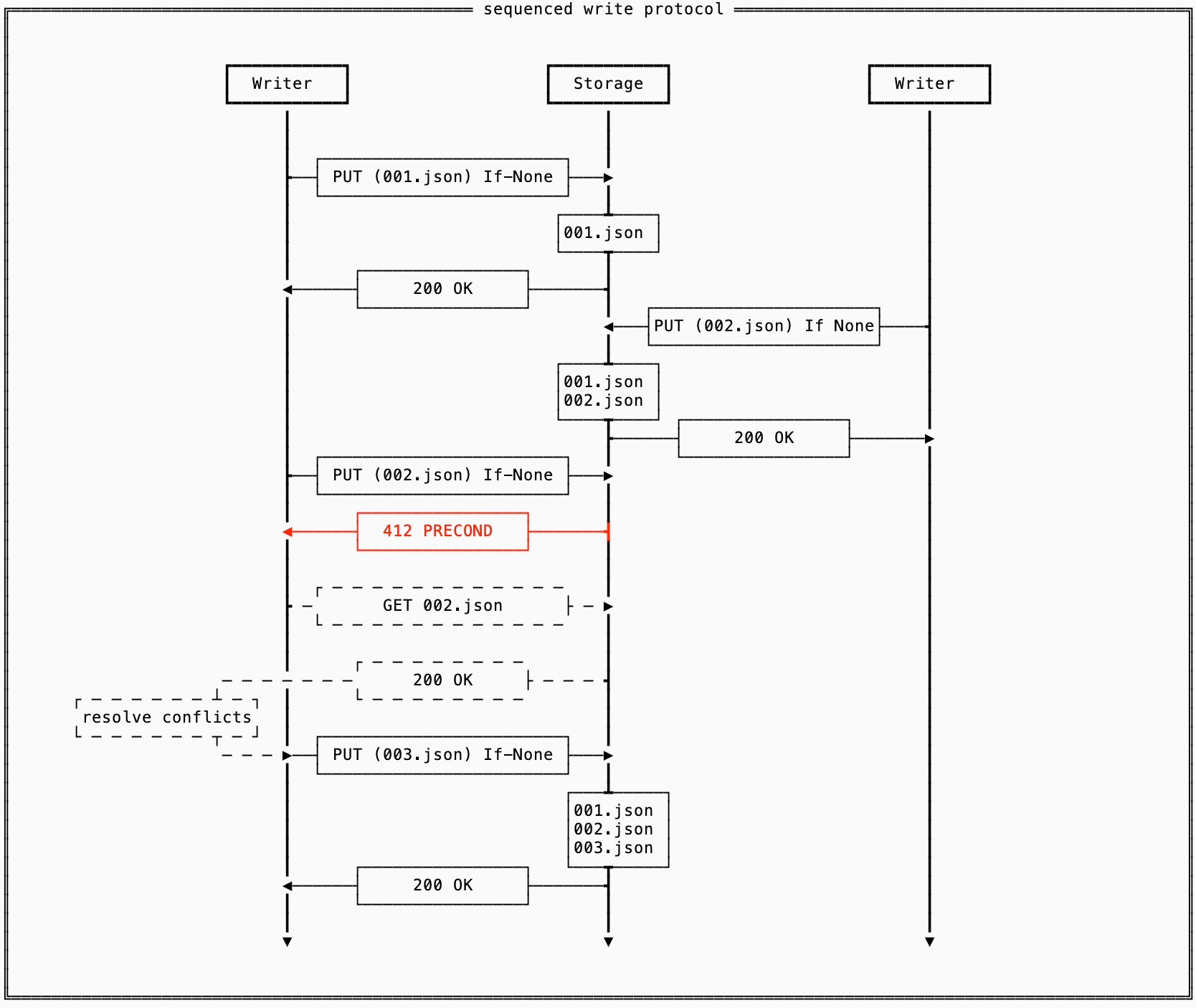
This protocol is an improvement on the original for two different use cases:
This protocol can be used for the original workload, where each file represents the full contents of the system. In this case, the behavior is the same except you have the ability to create cheap checkpoints of old versions of the data by simply leaving them around.
This protocol can also be used for an append-only workload that requires strict ordering of writes, such as WALs, where the state of the system is represented by reading all the files and resolving them in order. This protocol reduces the cost of contention from three S3 round trips to two by avoiding the
GETthat’s required for conflict resolution.
The downside of this protocol is that you now need some mechanism for garbage collection, or else your state on S3 will grow indefinitely.
single writer adaptation & epochs
Up until this point I’ve considered conflicts as recoverable errors. In many systems, including SlateDB, it’s much simpler to reason about a system that only allows a single writer. This allows the writer to provide transactional guarantees on writes, and can acknowledge writes as soon as they are logged in a WAL while still serving those writes in a read-your-write fashion. It also helps reduce contention, because a conflict only happens when a new writer is deployed.
If your system requires single-writer, the conflict resolution phase in the protocol should fail the writer (an indication that they have been fenced) instead of attempting to resolve the new data.
A natural extension of this is to allow conflict resolution behavior to depend on what the conflict was. SlateDB, for example, has different writer roles: there’s the main writer that accepts requests from clients that want to write data, but there’s also the garbage collector and the compactors which use the same protocol to interact with the files written to object storage.
The way we’ve designed this is to encode an epoch field inside the file that’s being written. Every role has its own epoch, and when a new instance of a role starts up it bumps only its own epoch. This allows us to detect which role is causing the conflict, if a writer reads back a file after a conflict and notices that its epoch is the same, then the change must’ve been caused from a non-conflicting role such as the compactor.
garbage collection
Focusing back in on the original workload, how do you know when to clean up old files when using the sequenced write protocol?
A naive, but practical, way to handle this is to configure a minimum age at which point it’s acceptable to begin cleaning up data. The garbage collector will scan all the files, deleting the ones that are older than this threshold.
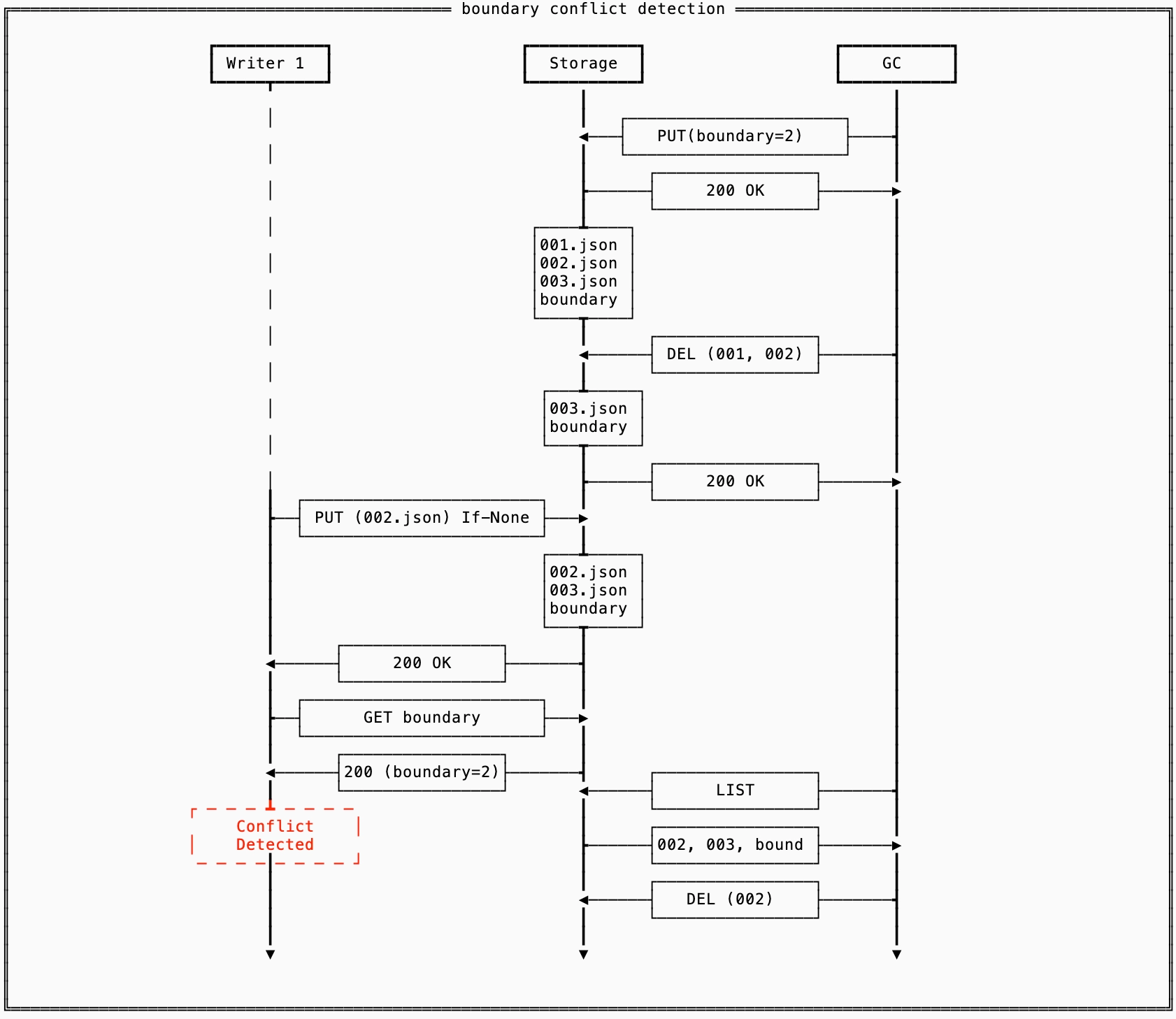
This isn’t, however, safe under all failure scenarios. If a writer stalls for longer than this minimum age, it might come back online and continue processing requests without noticing that it has inadvertently created a branch in the database:
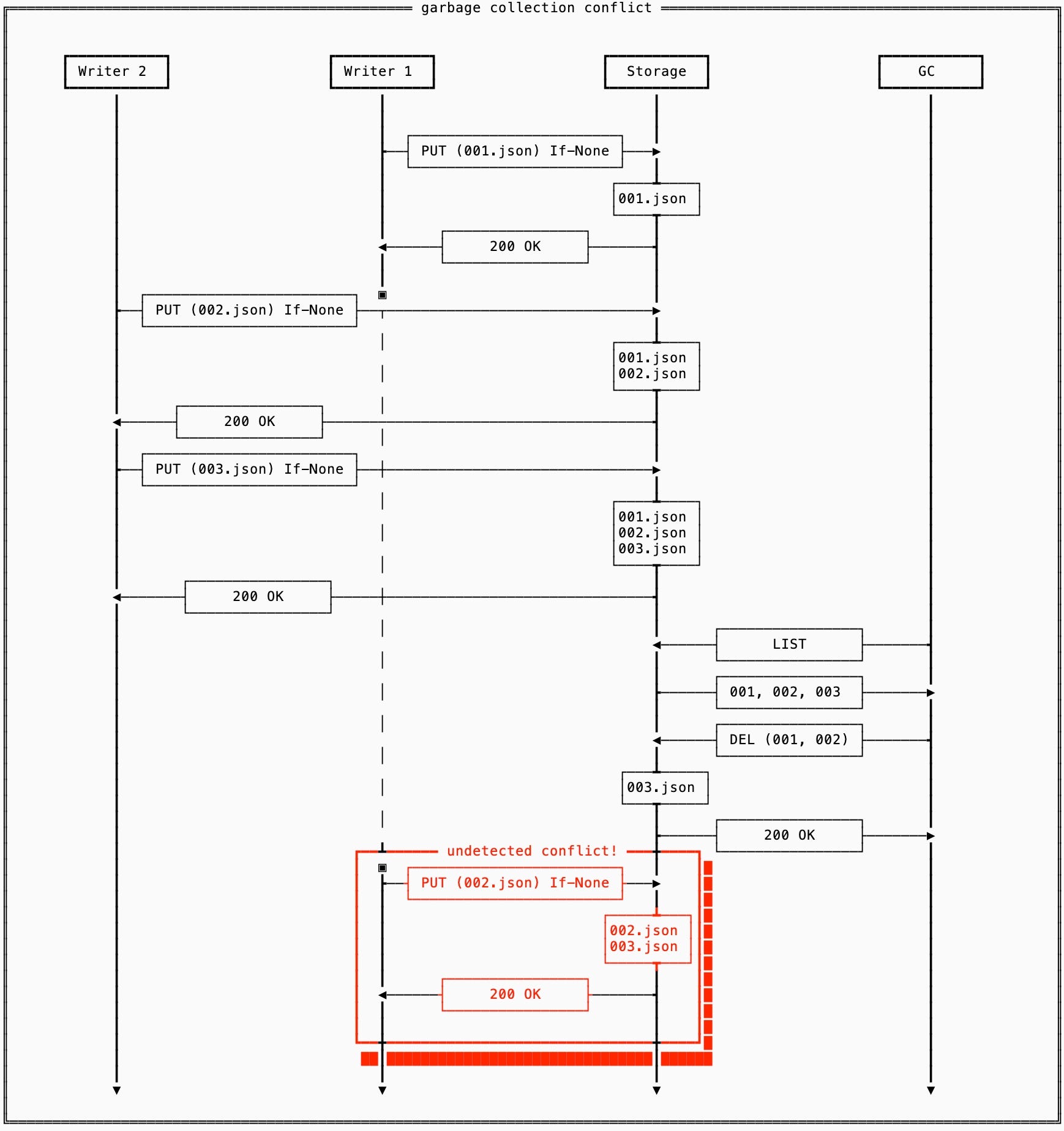
To make sure that cleaning up old files is safe, we amend the protocol by adding a boundary file2. This file is updated before any data is cleaned up, and is checked after any file is written to ensure that the previously described race does not happen.
When a write conflict is detected, the file remains and the old writer can either fail (single writer fencing) or attempt to read the latest file and resolve conflicts. Eventually the garbage collector will LIST and notice the conflicting file, cleaning it up.
If you, like me, like to squeeze every ounce of performance out of a protocol you might be a bit bummed about the need for the extra round trip after writing every additional file. Luckily, this can be optimized in situations with little conflicts.
If you remember the first section of this post we covered the GET If-None-Match API call that most object stores support. This API call doesn’t fetch the data if the file hasn’t changed, which makes it about 2-3x faster (p50 latency of ~10ms on S3). Since garbage collection doesn’t run too often, you can use this request and expect that most times your writer will not need to fetch the contents of the boundary file.
formal verification
Earlier I claimed that the first thing to evaluate is safety, and I skimmed over the details in this post but you can see the formally verified protocols in SlateDB using the Fizzbee formal specification language. When I first reviewed this, I had cold feet because I was worried that formal verification is something that requires lots of greek letters and difficult to read syntax. Turns out it’s quite simple, and if you are curious I urge you to read the full specification.
fsync()
That’s it for today! It’s fun to see such simple primitives compose into elegant, provably correct protocols for maintaining high-throughput transactions on top of object storage. If you’re encouraged to play around, give it a go yourself and start writing some formal verifications.
Putting the entire contents of your database in a single file is not suggested. Instead, this is used in practice with one layer of indirection, called a manifest file, to avoid rewriting your entire database data on every write.
Really liked this article! Do you know of any other articles about building distributed systems on top of conditional requests? The only one I can think of is Gunnar Morling's "Leader Election With S3 Conditional Writes."